
In the Code: User-Defined Function(UDF) in Spark SQL
This post illustrates the implementations of UDF in Spark SQL, where the targeted version is Spark 1.6.0 and the targeted language is Scala. I will talk about UDF in roughly two parts: registration and execution.
1. Registration
It is easy to register a UDF, either for use in the DataFrame DSL or SQL.
sqlContext.udf.register("strLen", (s: String) => s.length())
udf is a instance of class UDFRegistration for registering UDFs. There are more than 20 register methods which can be categorized into two classes: (1) UDAF(a.k.a UserDefinedAggregateFunction); (2) Scala closures(with 0 to 22 arguments). We only consider the latter ones here because they are more general and widely-used.
Without loss of generality, we will look into register method for Scala closure with one argument and I add some comments for better illustration.
private val functionRegistry = sqlContext.functionRegistry
/**
* Register a Scala closure of 1 arguments as user-defined function (UDF).
* @tparam RT return type of UDF.
* @tparam A1 argument type of UDF.
* @since 1.3.0
*/
def register[RT: TypeTag, A1: TypeTag](name: String, func: Function1[A1, RT]): UserDefinedFunction = {
// get the DataType of RT and A1 at run-time
val dataType = ScalaReflection.schemaFor[RT].dataType
val inputTypes = Try(ScalaReflection.schemaFor[A1].dataType :: Nil).getOrElse(Nil)
// builder :: Seq[Expression] -> Expression
def builder(e: Seq[Expression]) = ScalaUDF(func, dataType, e, inputTypes)
// functionRegistry is similar to a map storing key-value pair (name, function), which is a member of SQLContext
functionRegistry.registerFunction(name, builder)
// wrapper class
UserDefinedFunction(func, dataType, inputTypes)
}
It is straightforward to understand this code snippet with helpful comments except for ScalaUDF. For now, You can take it as another wrapper class which extends Expression for the returned value for UDF, which we will discuss later.
2. Execution
2.0 Parser(String -> Unresolved Logical Plan)
The parser just takes UDF as normal functions since they are essentially the same. I don’t think there is anything special to notice.
2.1 Analyzer(Unresolved Logical Plan -> Resolved Logical Plan)
As we have registered the UDF, when will it be retrieved after we explicitly call it(e.g., use it in a SQL query)? As the variable functionRegistry is a member of SQLContext as a catalog for storing functions, we can look into it to find out when it will be read. There is a method named lookupFunction which is designated for looking up functions. From the following comments(added by me), we learn that it would return a ScalaUDF instance after applying children to the builder.
override def lookupFunction(name: String, children: Seq[Expression]): Expression = {
// find corresponding builder
val func = synchronized {
functionBuilders.get(name).map(_._2).getOrElse {
throw new AnalysisException(s"undefined function $name")
}
}
// builder :: Seq[Expression] -> Expression
// apply children to builder, we would get a Expression, which is ScalaUDF
func(children)
}
Using Find Usages in IntelliJ IDEA, there are two usages of this method. For simplicity’s sake, we will ignore the underlying mechanism for running Hive on Spark.
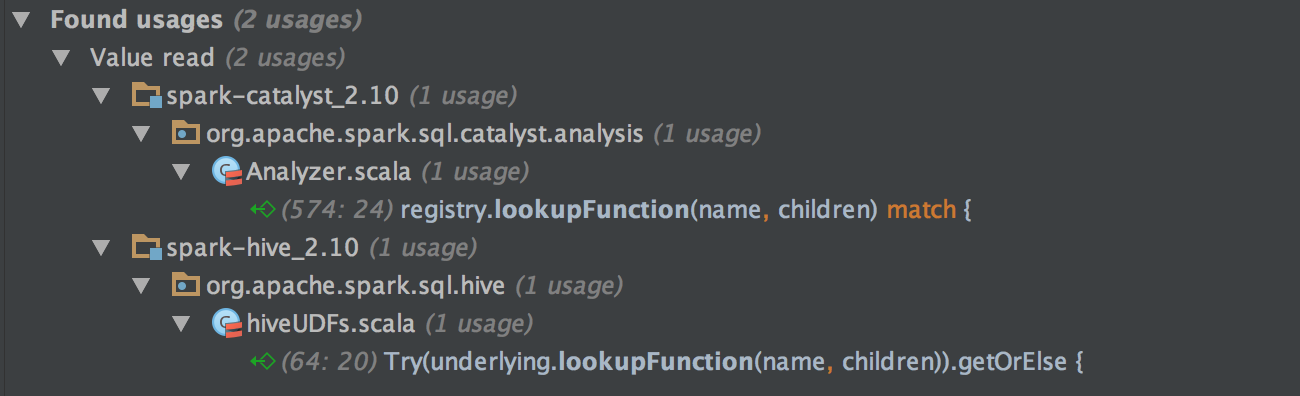
By digging into the first usage, we have the following code snippet, which is a Rule in Analyzer. We won’t cover too many details about them in this post, you can just consider them as some transformations applying on the syntax tree. For UDF, this rule will return the ScalaUDF instance since UDF falls into the other clause of case.
/**
* Replaces [[UnresolvedFunction]]s with concrete [[Expression]]s.
*/
object ResolveFunctions extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators {
case q: LogicalPlan =>
q transformExpressions {
case u if !u.childrenResolved => u // Skip until children are resolved.
case u @ UnresolvedFunction(name, children, isDistinct) =>
withPosition(u) {
registry.lookupFunction(name, children) match {
// DISTINCT is not meaningful for a Max or a Min.
case max: Max if isDistinct =>
AggregateExpression(max, Complete, isDistinct = false)
case min: Min if isDistinct =>
AggregateExpression(min, Complete, isDistinct = false)
// We get an aggregate function, we need to wrap it in an AggregateExpression.
case agg: AggregateFunction => AggregateExpression(agg, Complete, isDistinct)
// This function is not an aggregate function, just return the resolved one.
case other => other
}
}
}
}
}
There is actually another rule HandleNullInputsForUDF checking whether the parameters of UDF are null. Since it is trivial we won’t discuss it here. From now on, UDF is nothing different with some pre-defined functions like MAX.
2.2 Optimizer(Resolved Logical Plan -> Optimized Logical Plan)
I didn’t find any UDF-specific(or function-specific) things in Optimizer. Feel free to contact me if I neglect anything.
2.3 SparkPlanner(Optimized Logical Plan -> Physical Plan)
I didn’t find any UDF-specific(or function-specific) things in SparkPlanner. Feel free to contact me if I neglect anything.
2.4 PrepareForExecution(Physical Plan -> Executed Plan)
I didn’t find any UDF-specific(or function-specific) things in prepareForExecution. Feel free to contact me if I neglect anything.
2.5 Execute(Executed Plan -> RDD)
Without loss of generality, we could assume that the UDF is used in a filter clause as a predicate. By examining Filter’s doExecute method, we find that it would create a new Predicate(InternalRow -> Boolean) instance.
protected override def doExecute(): RDD[InternalRow] = {
val numInputRows = longMetric("numInputRows")
val numOutputRows = longMetric("numOutputRows")
child.execute().mapPartitionsInternal { iter =>
// predicate :: InternalRow -> Boolean
val predicate = newPredicate(condition, child.output)
iter.filter { row =>
numInputRows += 1
val r = predicate(row)
if (r) numOutputRows += 1
r
}
}
}
By jumping into the call stacks, it will eventually call create for creating a Predicate by employing some code generation techniques:
protected def create(predicate: Expression): ((InternalRow) => Boolean) = {
val ctx = newCodeGenContext()
// code generation for predicate method(ScalaUDF)
val eval = predicate.gen(ctx)
// create a predicate class
val code = s"""
public SpecificPredicate generate($exprType[] expr) {
return new SpecificPredicate(expr);
}
class SpecificPredicate extends ${classOf[Predicate].getName} {
private final $exprType[] expressions;
${declareMutableStates(ctx)}
${declareAddedFunctions(ctx)}
public SpecificPredicate($exprType[] expr) {
expressions = expr;
${initMutableStates(ctx)}
}
public boolean eval(InternalRow ${ctx.INPUT_ROW}) {
${eval.code}
return !${eval.isNull} && ${eval.value};
}
}"""
logDebug(s"Generated predicate '$predicate':\n${CodeFormatter.format(code)}")
val p = compile(code).generate(ctx.references.toArray).asInstanceOf[Predicate]
(r: InternalRow) => p.eval(r)
}
We could take the variable predicate as class ScalaUDF, and then we should look at the genCode method in ScalaUDF(remove some call stacks here). Since this method is kind of long to present(60+ lines), we will show it’s part here while adding some comments:
// define the UDF
ctx.addMutableState(funcClassName, funcTerm,
s"this.$funcTerm = ($funcClassName)((($scalaUDFClassName)expressions" +
s"[$funcExpressionIdx]).userDefinedFunc());")
// call the UDF
val callFunc = s"${ctx.boxedType(dataType)} $resultTerm = " +
s"(${ctx.boxedType(dataType)})${catalystConverterTerm}" +
s".apply($funcTerm.apply(${funcArguments.mkString(", ")}));"
return s"""
// codegen for children expressions
$evalCode
// Generate codes used to convert the arguments to Scala type for user-defined funtions
${converters.mkString("\n")}
// call the UDF
$callFunc
// return value
boolean ${ev.isNull} = $resultTerm == null;
${ctx.javaType(dataType)} ${ev.value} = ${ctx.defaultValue(dataType)};
if (!${ev.isNull}) {
${ev.value} = $resultTerm;
}
"""
It’s all done here. By explaining UDF in Spark SQL, we also have a rough overview of the underlying mechanism of Spark SQL. Feel free to contact me if you have any questions.