Niseko: Large-Scale Meta-Learning

Meta-learning has been used as an efficient technique to speed up building predictive models by learning useful experiences in a data-driven way.
Previous works either focus on devising meta-learning algorithms for a specific category of tasks or using it as a building block in a machine learning system.
Meta-learning data, however, can have impact much beyond this scope if it is publicly available.
It can enable machine learning practitioners to take data-driven decisions at all steps of their workflows.
We present Niseko, an open-source large-scale metalearning dataset with more than 5 million pipelines and 50 million pipeline runs on 300 datasets with clear-defined structures and easy-to-use APIs.
We demonstrate Niseko’s usefulness through several use cases.
Alpine Meadow: Interactive Automated Machine Learning
Statistical knowledge and domain expertise are key to extract actionable insights out of data, yet such skills rarely coexist together.
In Machine Learning, high-quality results are only attainable via mindful data preprocessing, hyperparameter tuning and model selection.
Domain experts are often overwhelmed by such complexity, de-facto inhibiting a wider adoption of ML techniques in other fields.
Existing libraries that claim to solve this problem, still require well-trained practitioners.
Those frameworks involve heavy data preparation steps and are often too slow for interactive feedback from the user, severely limiting the scope of such systems.
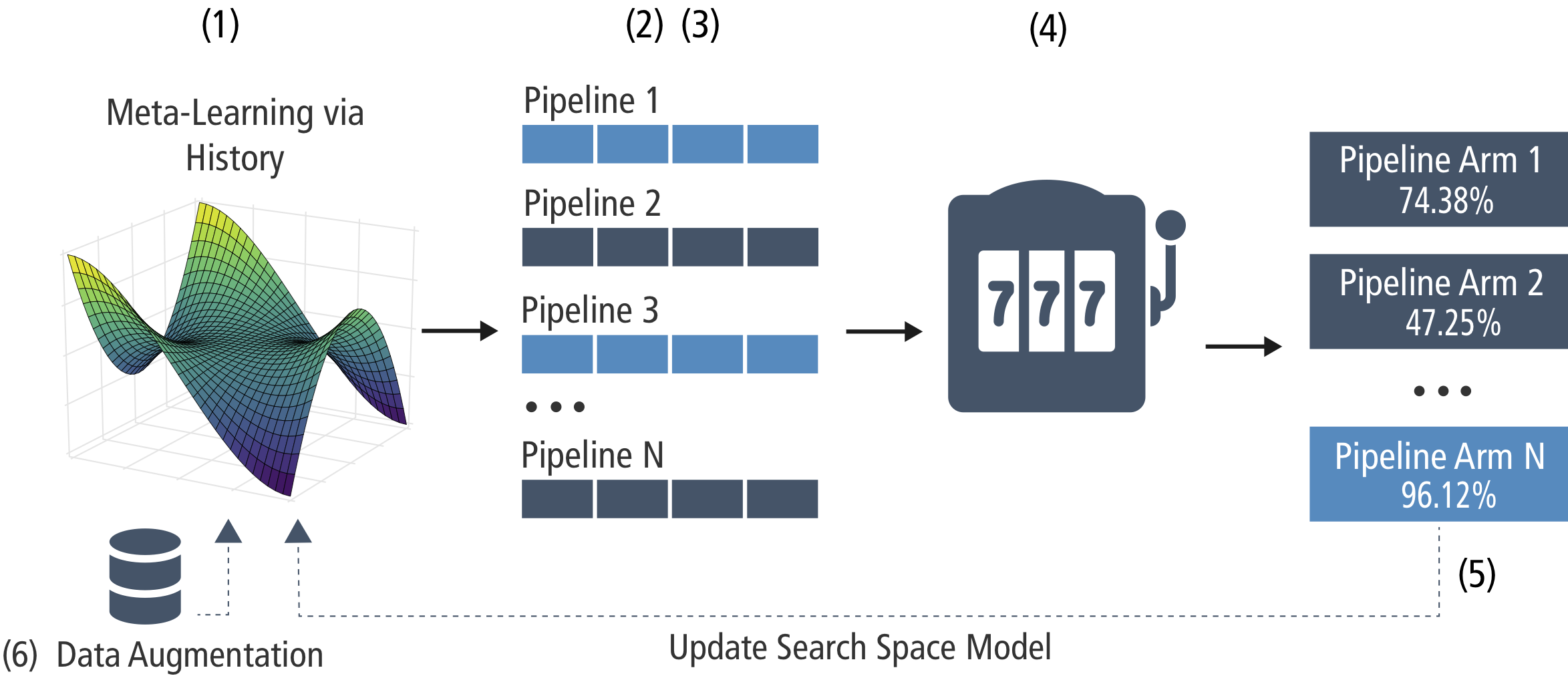
We present Alpine Meadow, a first Interactive Automated Machine Learning tool.
What makes our system unique is not only the focus on interactivity, but also the combined systemic and algorithmic design approach; on one hand we leverage ideas from query optimization, on the other we devise novel selection and pruning strategies combining cost-based Multi-Armed Bandits and Bayesian Optimization.
We evaluate our system on over 300 datasets and compare against other AutoML tools, including the current NIPS winner, as well as expert solutions.
Not only is Alpine Meadow able to significantly outperform the other AutoML systems while --- in contrast to the other systems --- providing interactive latencies, but also outperforms in 80% of the cases expert solutions over data sets we have never seen before.
Media Coverage:
[MIT News]
Query Re-optimization
Cost-based query optimizers remain one of the most important components of database management systems for analytic workloads.
Though modern optimizers select plans close to optimal performance in the common case, a small number of queries are an order of magnitude slower than they could be.
We investigate why this is still the case, despite decades of improvements to cost models, plan enumeration, and cardinality estimation.
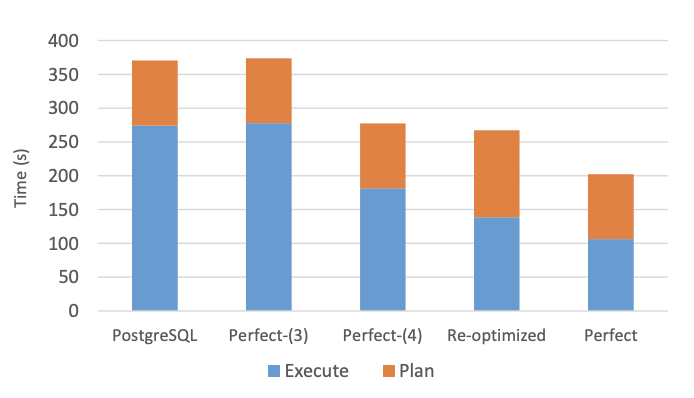
We demonstrate why we believe that a re-optimization mechanism is likely the most cost-effective way to improve end-to-end query performance. We find that even a simple re-optimization scheme can improve the latency of many poorly performing queries.
We demonstrate that re-optimization improves the end-to-end latency of the top 20 longest running queries in the Join Order Benchmark by 27%, realizing most of the benefit of perfect cardinality estimation.
DITA: Distributed In-Memory Trajectory Analytics
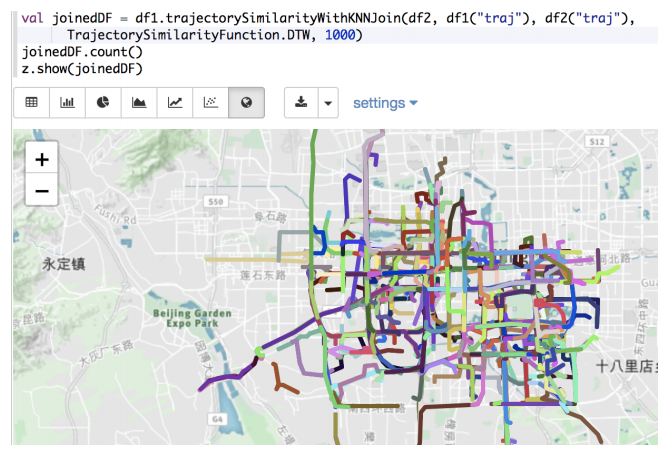
Trajectory analytics can benefit many real-world applications, e.g., frequent trajectory based navigation systems, road planning, car pooling, and transportation optimizations.
Existing algorithms focus on optimizing this problem in a single machine.
However, the amount of trajectories exceeds the storage and processing capability of a single machine, and it calls for large-scale trajectory analytics in distributed environments.
The distributed trajectory analytics faces challenges of data locality aware partitioning, load balance, easy-to-use interface, and versatility to support various trajectory similarity functions.
To address these challenges, we propose a distributed in-memory trajectory analytics system DITA.
We propose an effective partitioning method, global index and local index, to address the data locality problem. We devise cost-based techniques to balance the workload.
We develop a filter-verification framework to improve the performance.
Moreover, DITA can support most of existing similarity functions to quantify the similarity between trajectories.
We integrate our framework seamlessly into Spark SQL, and make it support SQL and DataFrame API interfaces.
We have conducted extensive experiments on real world datasets, and experimental results show that DITA outperforms existing distributed trajectory similarity search and join approaches significantly.
DIMA: Balance-Aware Distributed String-Similarity-Based Query Processing System
Data analysts spend more than 80% of time on data cleaning and integration in the whole process of data analytics due to data errors and inconsistencies.
Similarity-based query processing is an important way to tolerate the errors and inconsistencies.
However, similarity-based query processing is rather costly and traditional database cannot afford such expensive requirement.
We develop a distributed in-memory similarity-based query processing system called Dima.
Dima supports four core similarity operations, i.e., similarity selection, similarity join, top-k selection and top-k join.
Dima extends SQL for users to easily invoke these similarity-based operations in their data analysis tasks.
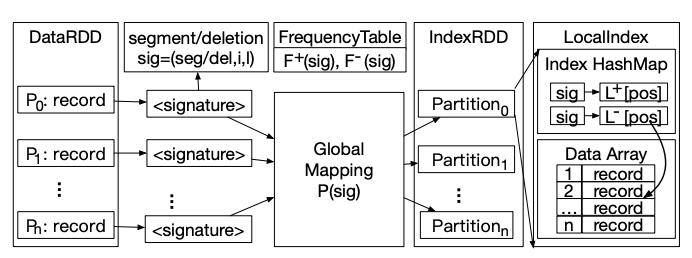
To avoid expensive data transmission in a distributed environment, we propose balance-aware signatures where two records are similar if they share common signatures, and we can adaptively select the signatures to balance the workload.
Dima builds signature-based global indexes and local indexes to support similarity operations.
Since Spark is one of the widely adopted distributed inmemory computing systems, we have seamlessly integrated Dima into Spark and developed effective query optimization techniques in Spark.
To the best of our knowledge, this is the first full-fledged distributed in-memory system that can support complex similarity-based query processing on largescale datasets. We have conducted extensive experiments on four real-world datasets.
Experimental results show that Dima outperforms state-of-the-art studies by 1-3 orders of magnitude and has good scalability.
K-Join: Knowledge-Aware Similarity Join
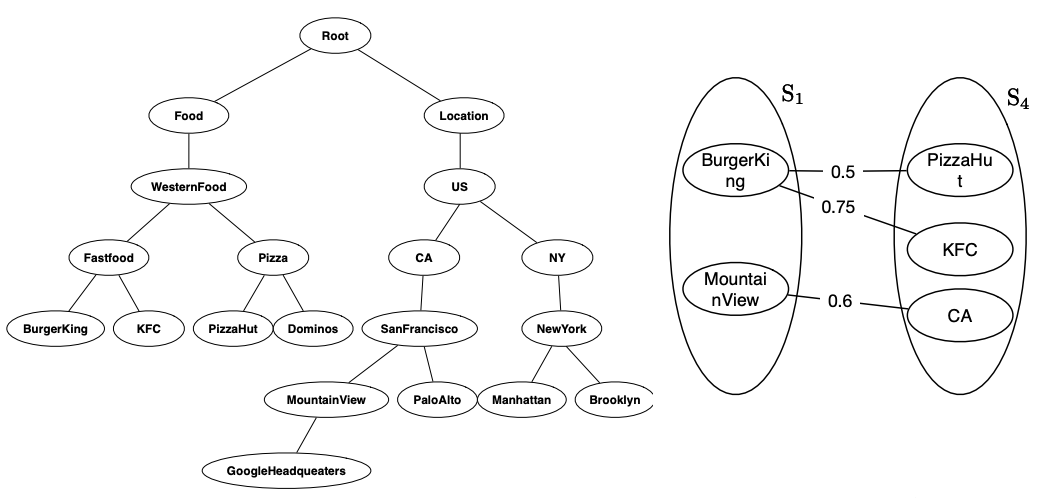
Similarity join is a fundamental operation in data cleaning and integration. Existing similarity-join methods utilize the string similarity to quantify the relevance but neglect the knowledge behind the data, which plays an important role in understanding the data.
Thanks to public knowledge bases, e.g., Freebase and Yago, we have an opportunity to use the knowledge to improve similarity join.
To address this problem, we study knowledge-aware similarity join, which, given a knowledge hierarchy and two collections of objects (e.g., documents), finds all knowledge-aware similar object pairs.
To the best of our knowledge, this is the first study on knowledge-aware similarity join.
There are two main challenges.
The first is how to quantify the knowledge-aware similarity.
The second is how to efficiently identify the similar pairs. To address these challenges, we first propose a new similarity metric to quantify the knowledge-aware similarity using the knowledge hierarchy.
We then devise a filter-and-verification framework to efficiently identify the similar pairs.
We propose effective signature-based filtering techniques to prune large numbers of dissimilar pairs and develop efficient verification algorithms to verify the candidates that are not pruned in the filter step.
Experimental results on real-world datasets show that our method significantly outperforms baseline algorithms in terms of both efficiency and effectiveness.
